深入探索 R 语言数据建模的神秘之旅
在当今数字化的时代,数据成为了宝贵的资源,而如何从海量的数据中挖掘出有价值的信息和知识,数据建模是关键的手段之一,R 语言作为一种强大的统计分析和数据处理工具,在数据建模方面具有广泛的应用,就让我们一起踏上 R 语言数据建模的精彩旅程。
想象一下,你手中有一堆杂乱无章的数据,就像是一堆没有头绪的拼图碎片,而 R 语言就像是一把神奇的拼图工具,能够帮助你将这些碎片拼凑成一幅清晰、有意义的画面。
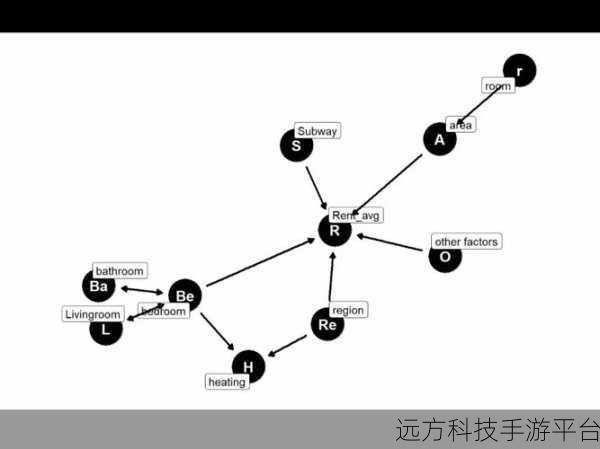
数据的收集和整理是建模的基础,这就好比你在准备建造一座房子,需要先准备好充足且质量良好的建筑材料,在 R 语言中,你可以使用各种函数和包来读取不同格式的数据,CSV、Excel 等,并对数据进行清洗、预处理,去除重复值、处理缺失值等,让数据变得干净、整齐。
是对数据的探索性分析,这一步就像是在提前了解你的拼图全貌,通过绘制图表、计算统计量等方式,来了解数据的分布、趋势、相关性等特征,这有助于你发现数据中的潜在规律和异常情况。
选择合适的建模方法至关重要,R 语言提供了丰富的建模函数和算法,比如线性回归、逻辑回归、聚类分析、决策树等等,这就像是在众多的拼图模板中选择最适合你这幅拼图的那一个。
在建模过程中,参数的调整和优化是必不可少的,这就像是在微调拼图的每一块,让它们更加契合,通过不断地试验和比较,找到最优的参数组合,以提高模型的性能和准确性。
模型评估是检验模型好坏的重要环节,就像你完成拼图后,要检查是否完整、美观一样,常用的评估指标有准确率、召回率、F1 值等,根据具体的问题和需求选择合适的评估指标。
不要忘记对模型进行部署和应用,将训练好的模型应用到实际的数据中,产生有价值的预测和决策。
为了让大家更好地理解 R 语言数据建模的流程,我们来玩一个小游戏,假设我们有一组学生的考试成绩数据,包括语文、数学、英语等科目。
游戏玩法:
1、将数据导入到 R 语言中,并进行数据清洗和预处理。
2、通过探索性分析,观察各科成绩的分布情况。
3、选择一种建模方法,比如线性回归,来预测学生的总成绩。
4、调整模型参数,比如学习率、迭代次数等,优化模型。
5、使用评估指标,如均方误差,来评估模型的性能。
操作方式:
1、打开 R 语言的编程环境,如 RStudio。
2、使用 read.csv() 函数读取数据文件。
3、运用 summary() 函数查看数据的基本情况,使用 na.omit() 函数处理缺失值。
4、使用 plot() 函数绘制各科成绩的直方图、箱线图等。
5、调用 lm() 函数进行线性回归建模,并通过 coef() 函数查看模型参数。
问答:
1、在 R 语言中,如何处理数据中的异常值?
2、怎样选择最适合数据的建模方法?
3、模型评估指标除了上述提到的,还有哪些常用的?