探索 Python 爬取动态网页的神秘世界
在当今数字化的时代,网页数据的获取变得越来越重要,Python 作为一种强大的编程语言,为我们提供了丰富的工具和库来爬取网页数据,而当面对动态生成的网页框架时,要成功爬取所需的数据,就需要掌握一定的知识和运用合适的库。
动态生成的网页相较于静态网页更加复杂,因为它们的数据并非在页面加载时一次性全部呈现,而是通过 JavaScript 等技术在用户与页面交互时动态加载,这就给爬虫带来了挑战,因为传统的爬虫方法可能无法获取到完整的数据。
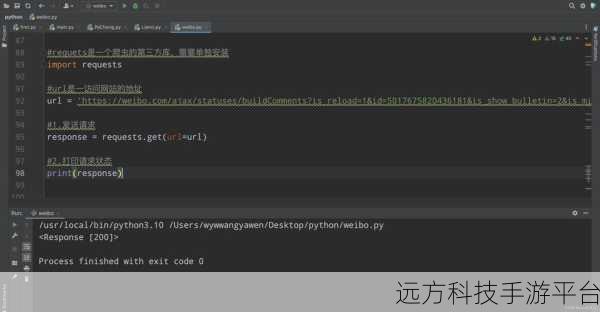
要应对这种情况,首先需要了解 HTTP 协议的基本原理,HTTP 是网页通信的基础,掌握它有助于理解网页请求和响应的过程,了解常见的请求方法,如 GET 和 POST,以及请求头和响应头中的关键信息,对于正确地与服务器进行交互至关重要。
接下来是 JavaScript 知识,虽然 Python 本身不直接处理 JavaScript,但了解 JavaScript 的运行机制可以帮助我们预测和处理动态加载的数据,某些网页可能会在用户滚动页面或点击某个按钮时触发 JavaScript 函数来加载更多内容。
在库方面,Selenium 是一个常用的选择,它可以模拟浏览器的行为,包括页面滚动、点击等操作,从而获取到动态生成的数据,使用 Selenium 时,需要安装相应的浏览器驱动,如 ChromeDriver 或 GeckoDriver。
Pyppeteer 也是一个不错的库,它基于 Puppeteer,提供了类似 Selenium 的功能,但可能在某些情况下性能更好。
除了这些,还需要掌握网页解析的技巧,BeautifulSoup 和 lxml 是两个常用的网页解析库,可以帮助我们从获取到的 HTML 代码中提取所需的数据。
对于爬取动态网页,还需要注意反爬虫机制,许多网站会采取措施来防止爬虫的过度访问,如设置访问频率限制、验证码等,在爬取时,要遵循网站的规则,并采取适当的策略来避免被封禁。
下面给大家介绍一个简单的游戏,帮助大家更好地理解动态网页爬取的概念。
游戏名称:“数据寻宝”
游戏玩法:
假设我们有一个虚拟的动态网页,页面上会随机出现一些隐藏的数据宝箱。
玩家需要使用 Python 编写爬虫代码来获取这些宝箱中的数据。
游戏操作方式:
1、玩家首先需要分析网页的结构和数据加载方式。
2、然后选择合适的库和技术来实现爬虫功能。
3、在编写代码的过程中,要处理可能出现的各种情况,如页面加载延迟、数据加密等。
4、成功获取到数据宝箱中的数据即为胜利。
问答:
1、Python 中除了 Selenium 和 Pyppeteer,还有其他模拟浏览器操作的库吗?
2、如何判断一个网页是否采用了动态生成技术?
3、在爬取动态网页时,如何处理验证码的问题?